Python自动化 | 比对两份Excel/Word文件
如果你经常与Excel或Word打交道,那么从两份表格/文档中找到不一样的元素是一件让人很头疼的工作,当然网上有很多方法、第三方软件教你如何对比两份文件。本文就将以两份真实的Excel/Word文件为例,讲解如何使用Python光速对比并提取文件中的不同之处!
比较Excel
Excel用例
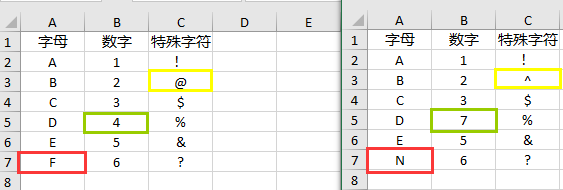
可以看到上方两个Excel表格中共有四处不同,现在我们使用Python来快速定位这五处不同。
import pandas as pd #没有pandas模块,记得安装
import numpy as np
df1 = pd.read_excel('data1.xlsx')
df2 = pd.read_excel('data2.xlsx')
comparison_values = df1.values == df2.values
rows,cols=np.where(comparison_values==False)
for item in zip(rows,cols):
df1.iloc[item[0], item[1]] = '{} --> {}'.format(df1.iloc[item[0], item[1]],df2.iloc[item[0], item[1]])
df1.to_excel('diff.xlsx',index=False,header=True)
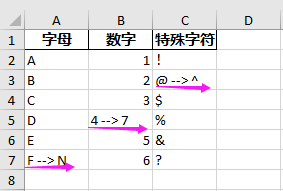
现在就生成了一个新的Excel来提示我们哪里发生了变化
比较Word
我们还是创建两份有区别的Word文档

from docx import Document # 需安装python-docx模块
import re
def getText(wordname):
'''
提取文字
'''
d = Document(wordname)
texts = []
for para in d.paragraphs:
texts.append(para.text)
return texts
def is_Chinese(word):
'''
识别中文
'''
for ch in word:
if '\u4e00' <= ch <= '\u9fff':
return True
return False
def msplit(s, seperators = ',|\.|\?|,|。|?|!|、'):
'''
根据标点符号分句
'''
return re.split(seperators, s)
def readDocx(docfile):
'''
读取文档
'''
print(f"======正在读取{docfile}======")
paras = getText(docfile)
segs = []
for p in paras:
temp = []
for s in msplit(p):
if len(s) > 2:
temp.append(s.replace(' ', ""))
if len(temp) > 0:
segs.append(temp)
return segs
def comparsion(doc1,doc2,p,s):
if doc1 == doc2:
print('两个word完全一致')
else:
if doc1[p][s] != doc2[p][s]:
print(f"第{p+1}段,第{s+1}句不相同: {doc1[p][s]} ----> {doc2[p][s]}")
doc1 = readDocx('data1.docx')
doc2 = readDocx('data2.docx')
for p in range(len(doc1)):
for s in range(len(doc1[p])):
comparsion(doc1, doc2, p, s)

您可能也喜欢

了解 Linux 中的 SUID、SGID 和 Sticky bit

docker部署Elasticsearch集群
